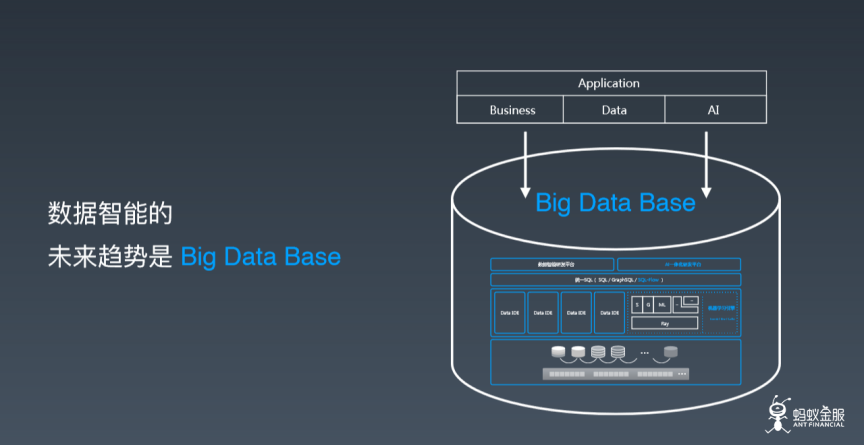
深度学习作为人工智能领域的重要分支,其性能表现很大程度上依赖于数据的质量与处理方式。数据处理是连接原始数据与算法模型的桥梁,是决定模型能否有效学习、泛化能力是否强大的关键前置步骤。本文将系统概述深度学习中的主要数据处理方法,涵盖数据采集、清洗、标注、增强及标准化等核心环节。
一、数据采集与理解
数据处理的起点是数据采集。高质量的数据集应具备代表性、多样性和规模性。在采集阶段,需明确数据的来源(如公开数据集、网络爬虫、传感器采集等),并初步理解数据的特征,包括数据类型(如图像、文本、音频、时序数据)、数据维度、潜在的数据分布以及可能存在的噪声和缺失情况。这一阶段的核心目标是构建一个能充分反映现实世界复杂性的初始数据池。
二、数据清洗与预处理
原始数据往往包含大量“杂质”,直接用于训练会导致模型学习到错误模式。数据清洗旨在消除这些噪声和错误,主要任务包括:
- 缺失值处理:对于缺失的数据点,可采用删除、均值/中位数/众数填充、插值法或基于模型预测等方法。
- 异常值检测与处理:利用统计方法(如3σ原则)、箱线图或孤立森林等算法识别异常点,并根据其性质决定是修正、删除还是保留。
- 噪声过滤:针对特定数据类型使用平滑技术(如移动平均滤波处理时序数据)或去噪算法(如图像的高斯滤波)。
- 数据格式统一:确保数据格式(如日期、编码)的一致性,便于后续处理。
三、数据标注与标签工程
对于监督学习任务,高质量的人工标注至关重要。这包括分类标签、边界框(目标检测)、像素级分割掩码(图像分割)或序列标注(NLP)。标注过程需确保准确性、一致性和完整性。标签工程(如将多分类问题转化为多个二分类问题、设计标签平滑策略以防止模型过拟合)也是提升模型性能的有效手段。对于无监督或半监督学习,则可能涉及伪标签生成或聚类标签分配。
四、数据增强与扩充
深度学习模型通常需要大量数据来避免过拟合,而数据增强技术可以在不增加新数据的前提下,通过对现有数据进行一系列变换来扩充数据集,提升模型的泛化能力和鲁棒性。
- 图像数据:常用方法包括几何变换(旋转、翻转、裁剪、缩放)、颜色空间变换(亮度、对比度调整)、添加噪声、随机擦除(CutOut)以及混合样本(MixUp, CutMix)等。
- 文本数据:可采用同义词替换、随机插入、删除、交换词序、回译(翻译成其他语言再译回)等方法。
- 音频数据:包括添加背景噪声、改变音调、语速或进行时域/频域掩蔽。
五、数据标准化与特征工程
为了使模型训练更稳定、高效,通常需要对数据进行标准化或归一化处理,将特征缩放到一个统一的尺度(如[0, 1]或均值为0、方差为1)。常见方法有Min-Max标准化和Z-Score标准化。虽然深度学习以其强大的特征自动学习能力著称,但适当的特征工程(如基于领域知识构造新特征、特征选择以降维)仍能有效引导模型,尤其在数据量有限时。
六、数据集划分与采样
将处理后的数据划分为训练集、验证集和测试集是评估模型泛化能力的标准做法。通常采用随机分层采样以确保各类别比例在子集中与总体一致。对于类别不平衡的数据集,需采用过采样(如SMOTE)、欠采样或调整损失函数权重等策略,防止模型偏向多数类。
七、数据流水线与批处理
在模型训练过程中,高效的数据加载和预处理流水线(Data Pipeline)至关重要。现代深度学习框架(如TensorFlow/PyTorch)提供了数据加载器(DataLoader),支持多线程预读取、在线数据增强和批处理(Batching),将数据以批(Batch)的形式送入模型,这既提高了GPU利用率,也引入了批归一化等优化技术的可能性。
###
数据处理并非一次性的前端工作,而是一个与模型开发迭代紧密互动的循环过程。模型在验证集/测试集上的表现常常会揭示数据中的新问题(如标注错误、分布偏移),进而驱动新一轮的数据清洗或增强。因此,建立系统化、可复现的数据处理流程,是任何成功深度学习项目的坚实基石。理解并熟练运用上述方法,将帮助从业者从“数据海洋”中提炼出真正的“信息黄金”,赋能模型实现卓越性能。