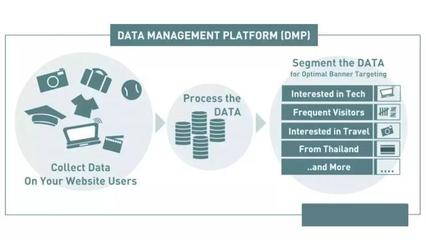
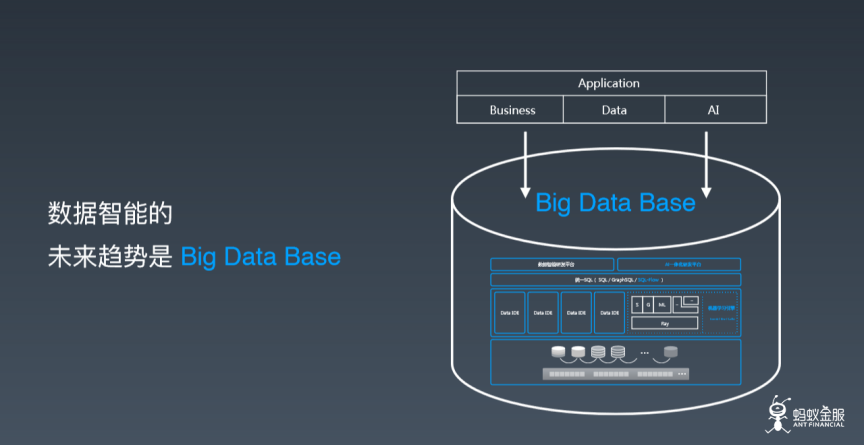
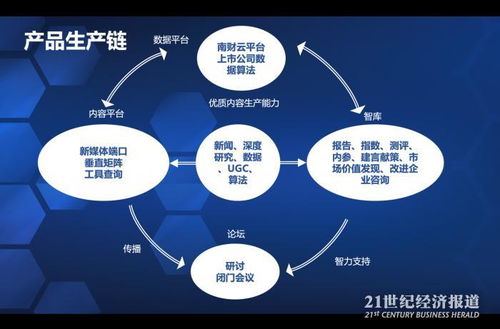
随着大数据时代的到来,文字云作为一种直观的数据可视化工具,被广泛应用于舆情分析、文本挖掘和商业决策等领域。文字云通过视觉化展示文本中高频词汇的大小和颜色,帮助用户快速把握文本的核心内容。本文将系统介绍文字云资料处理的完整流程,涵盖数据收集、预处理、分析和可视化等关键环节。
一、数据收集与整理
文字云构建的第一步是获取原始文本数据。常见的数据来源包括:社交媒体评论、新闻文章、用户反馈、学术论文等。数据收集时需注意样本的代表性和数据量,通常建议文本规模在千字以上,以确保统计结果的可靠性。收集到的原始数据往往包含大量无关信息,需要进行初步清洗,如去除广告内容、重复文本和无关符号。
二、数据预处理关键技术
预处理是文字云生成的关键环节,主要包括以下步骤:
- 文本清洗:去除特殊字符、标点符号和数字,保留核心文字内容
- 分词处理:根据语言特性进行词语切分,中文需使用分词工具如Jieba,英文则依据空格分隔
- 停用词过滤:移除常见但无实际意义的词汇(如“的”、“是”、“the”、“and”等)
- 词形还原:将词语统一转换为原型(如“running”还原为“run”)
- 词频统计:计算每个词语在文本中出现的频率
三、数据处理算法优化
为提高文字云的质量和可读性,可采用以下优化策略:
- 设置词频阈值,过滤过低或过高的异常值
- 实施同义词合并,避免语义重复
- 添加领域词典,确保专业术语的正确识别
- 采用TF-IDF算法,提升关键词的区分度
四、可视化呈现与解读
数据处理完成后,通过专业的文字云生成工具(如WordCloud、Tagxedo等)进行可视化呈现。在布局设计时应注意:
- 颜色搭配要符合视觉习惯和主题需求
- 字体大小需准确反映词频差异
- 布局密度要适中,保证可读性
- 可添加交互功能,支持点击查看详细数据
五、应用场景与注意事项
文字云在以下场景中具有显著价值:
- 舆情监控:快速掌握社交媒体热点话题
- 市场研究:分析用户评论和产品反馈
- 学术研究:梳理文献关键词分布
- 内容优化:指导网站SEO和内容创作
在使用过程中需注意:文字云仅展示词频信息,无法体现语义关系和上下文语境,因此需要结合其他文本分析方法进行综合判断。同时,要警惕数据偏见问题,确保样本的代表性和处理过程的客观性。
文字云资料处理是一个系统的数据分析过程,从原始文本到直观可视化的转化,需要严谨的数据处理方法和专业的可视化技巧。随着自然语言处理技术的不断发展,文字云的分析深度和应用范围将持续扩展,为各行业的文本分析提供更有力的支持。